SESC源码阅读——Pipeline View
3.Pipeline view
在SESC中,GProcessor(Generic Processor)类的对象协调不同流水线阶段间的交互。GProcessor对象的对外接口是advanceClock()函数。advanceClock()函数于每个时钟周期将流水线往前推进一个阶段。为了完成这项工作,它首先调用一个函数获取指令并将该指令放到指令队列中。然后,它再调用一个函数从队列中发射指令到一个调度窗口。存在两个可以调度和执行指令的clusters,一个用于整型指令,一个用于浮点型指令,并且每一个都拥有它们自己的调度窗口。指令调度和执行被模拟器的其他部分处理。最后,一个函数会被调用,以将已经执行过的指令从reorder buffer中退出。
//src/libcore/GProcessor.h
class GProcessor {
private:
protected:
// Per instance data
const CPU_t Id;
const int32_t FetchWidth;
const int32_t IssueWidth;
const int32_t RetireWidth;
const int32_t RealisticWidth;
const int32_t InstQueueSize;
bool InOrderCore;
const size_t MaxFlows;
const size_t MaxROBSize;
GMemorySystem *memorySystem;
FastQueue<DInst *> ROB;
FastQueue<DInst *> replayQ;
LDSTQ lsq;
//......
ClusterManager clusterManager;
// Normal Stats
GStatsAvg robUsed;
// Energy Counters
GStatsEnergyBase *renameEnergy;
GStatsEnergyBase *robEnergy;
GStatsEnergyBase *wrRegEnergy[3]; // 0 INT, 1 FP, 2 NONE
GStatsEnergyBase *rdRegEnergy[3]; // 0 INT, 1 FP, 2 NONE
public:
// Inserts a fid in the processor. Notice that before called it must be sure
// that availableFlows is bigger than one
virtual void switchIn(Pid_t pid) = 0;
// Extracts the pid. Precondition: the pid should be running in the processor
virtual void switchOut(Pid_t pid) = 0;
virtual long long getAndClearnGradInsts(Pid_t pid) = 0; // Must be called only by RunningProcs
virtual long long getAndClearnWPathInsts(Pid_t pid) = 0; // Must be called only by RunningProcs
// Returns the number of extra threads (switchIn) that processor may accept
virtual size_t availableFlows() const = 0;
virtual void goRabbitMode(long long n2Skip) = 0;
// Find a victim pid that can be switchout
virtual Pid_t findVictimPid() const = 0;
// Different types of cores extend this function. See SMTProcessor and
// Processor.
virtual void advanceClock() = 0;
virtual bool hasWork() const=0;
//......
}
可以看出在GProcessor类中advanceClock()是一个虚函数,不同类型的核要扩展该函数,Processor类和SMTProcessor类均是其子类,如下:
//src/libcore/Processor.h
class Processor:public GProcessor {
//......
}
void Processor::advanceClock()
{
#ifdef TS_STALL
if (isStall()) return;
#endif
clockTicks++;
// GMSG(!ROB.empty(),"robTop %d Ul %d Us %d Ub %d",ROB.getIdFromTop(0)
// ,unresolvedLoad, unresolvedStore, unresolvedBranch);
// Fetch Stage
if (IFID.hasWork() ) {
IBucket *bucket = pipeQ.pipeLine.newItem();
if( bucket ) {
IFID.fetch(bucket);
}
}
// ID Stage (insert to instQueue)
if (spaceInInstQueue >= FetchWidth) {
IBucket *bucket = pipeQ.pipeLine.nextItem();
if( bucket ) {
I(!bucket->empty());
// I(bucket->top()->getInst()->getAddr());
spaceInInstQueue -= bucket->size();
pipeQ.instQueue.push(bucket);
}else{
noFetch2.inc();
}
}else{
noFetch.inc();
}
// RENAME Stage
if ( !pipeQ.instQueue.empty() ) {
spaceInInstQueue += issue(pipeQ);
// spaceInInstQueue += issue(pipeQ);
}
retire();
}
//src/libcore/SMTProcessor.h
class SMTProcessor:public GProcessor {
//......
}
void SMTProcessor::advanceClock()
{
clockTicks++;
//......
}
流水线建模中所有类的交互如下: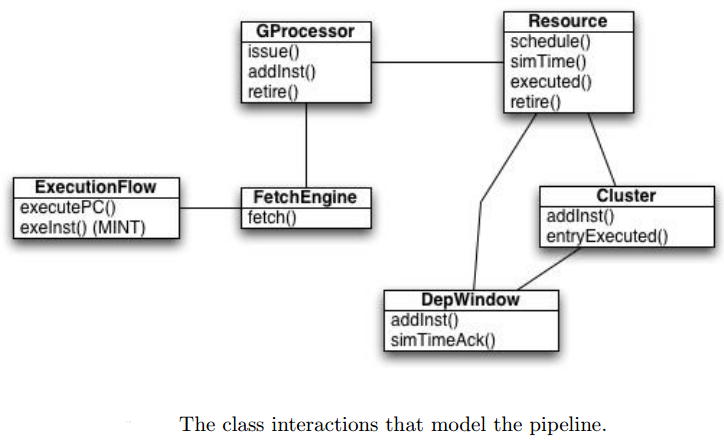
3.1 取指/译码(Fetch/Decode)
取指是流水线的第一个阶段。在该阶段中,指令从I-cache中取出并被放到流水线中。在经典的配置中,取指单元每个周期最多取出4条指令。取指单元也会预测分支走向,并获取该预测分支路径下的指令。 处理取指的类是FetchEngine。它的对外接口是fetch()函数。
//src/libcore/FetchEngine.h
class FetchEngine {
private:
// Static data
static long long nInst2Sim;
static long long totalnInst;
const int32_t Id;
const int32_t cpuId;
GMemorySystem *gms;
GProcessor *gproc;
Pid_t pid;
BPredictor *bpred;
//......
// Fills the current fetch buffer.
// Always fetches at most fetchWidth instructions
void fetch(IBucket *buffer, int32_t fetchMax = -1);
// Fake fetch. Fills the buffer with fake (mispredicted) instructions
// Only active is SESC_MISPATH def'd
void fakeFetch(IBucket *buffer, int32_t fetchMax = -1);
void realFetch(IBucket *buffer, int32_t fetchMax = -1);
//......
}
//src/libcore/FetchEngine.cpp
void FetchEngine::fetch(IBucket *bucket, int32_t fetchMax)
{
if(missInstID) {
fakeFetch(bucket, fetchMax);
}else{
realFetch(bucket, fetchMax);
}
if(enableICache && !bucket->empty()) {
szFS.sample(bucket->size());
if (bucket->top()->getInst()->isStoreAddr())
IMemRequest::create(bucket->topNext(), gms, bucket);
else
IMemRequest::create(bucket->top(), gms, bucket);
}else{
// Even if there are no inst to fetch, bucket.empty(), it should
// be markFetched. Otherwise, we would loose count of buckets
bucket->markFetchedCB.schedule(IL1HitDelay);
}
}
fetch()函数尝试从I-cache中获取可配置数量的指令。fetch()函数也模型化一个分支预测器。fetch()函数与ExecutionFlow类进行交互。特别地,它调用ExecutePC()函数从cache得到下一条指令的地址。然后,它为这个地址向I-cache产生一个请求。当所有的指令从I-cache返回时,这些指令成束地被传递到流水线的下一个阶段。
//src/libcore/FetchEngine.cpp
void FetchEngine::realFetch(IBucket *bucket, int32_t fetchMax)
{
int32_t n2Fetched=fetchMax > 0 ? fetchMax : FetchWidth;
maxBB = BB4Cycle; // Reset the max number of BB to fetch in this cycle (decreased in processBranch)
// This method only can be called once per cycle or the restriction of the
// BB4Cycle would not enforced
I(pid>=0);
I(maxBB>0);
I(bucket->empty());
I(missInstID==0);
Pid_t myPid = flow.currentPid();
//......
do {
nGradInsts++; // Before executePC because it can trigger a context switch
DInst *dinst = flow.executePC();
if (dinst == 0)
break;
//......
const Instruction *inst = dinst->getInst();
//......
instFetched(dinst);
bucket->push(dinst);
//......
n2Fetched--;
bbSize++;
fbSize++;
if(inst->isBranch()) {
szBB.sample(bbSize);
bbSize=0;
if (!processBranch(dinst, n2Fetched)) {
break;
}
}
}while(n2Fetched>0 && flow.currentPid()==myPid);
//......
ushort tmp = FetchWidth - n2Fetched;
totalnInst+=tmp;
if( totalnInst >= nInst2Sim ) {
MSG("stopSimulation at %lld (%lld)",totalnInst, nInst2Sim);
osSim->stopSimulation();
}
nFetched.add(tmp);
}
译码(如:将指令从ISA格式转变为内部格式)发生在模拟的程序被读入且每条二进制指令被译码成Instruction对象时。因此,在成束地将指令传递到流水线的下一个阶段时,FetchEngine类简单地增加一个译码延时惩罚。
SESC支持若干不同的分支预测器。预测器的选择和它大小的决定在运行时进行。因为分支预测在取指单元中完成,所以FetchEngine类也负责处理预测器的选择和它大小的决定。
如果指令是一个分支,FetchEngine类会调用processBranch()函数,其完成分支预测。如果分支预测是错误的,processBranch()函数将会通过标记误预测模仿流水线刷新(pipeline flush)。processBranch()函数代码如下:
//src/libcore/FetchEngine.cpp
bool FetchEngine::processBranch(DInst *dinst, ushort n2Fetched)
{
const Instruction *inst = dinst->getInst();
InstID oracleID = flow.getNextID();
#ifdef BPRED_UPDATE_RETIRE
PredType prediction = bpred->predict(inst, oracleID, false);
if (!dinst->isFake())
dinst->setBPPred(bpred, oracleID);
#else
PredType prediction = bpred->predict(inst, oracleID, !dinst->isFake());
#endif
if( oracleID != inst->calcNextInstID() ) {
fbSizeBB--;
if( fbSizeBB == 0 ) {
szFB.sample(fbSize);
fbSize=0;
fbSizeBB = BB4Cycle;
}
}
if(prediction == CorrectPrediction) {
if( oracleID != inst->calcNextInstID() ) { //Taken
// Only when the branch is taken check maxBB
maxBB--;
if( maxBB == 0 ) {
// No instructions fetched (stall)
if (missInstID==0)
nDelayInst2.add(n2Fetched);
return false;
}
}
return true;
}
#ifdef SESC_MISPATH
if (missInstID==0 && !dinst->isFake()) { // Only first mispredicted instruction
I(missFetchTime == 0);
missFetchTime = globalClock;
missInstID = inst->calcNextInstID();
dinst->setFetch(this);
}
#else
I(missInstID==0);
I(missFetchTime==0);
missFetchTime = globalClock;
missInstID = inst->calcNextInstID();
if( BTACDelay ) {
if( prediction == NoBTBPrediction && inst->doesJump2Label() ) {
nBTAC.inc();
unBlockFetchCB.schedule(BTACDelay);
}else{
dinst->setFetch(this); // blocked fetch (awaked in Resources)
}
}else{
dinst->setFetch(this); // blocked fetch (awaked in Resources)
}
#endif // SESC_MISPATH
return false;
}
bpred的定义为BPredictor *bpred;,BPredictor类内有一个 BPred *pred;定义,BPred是所有分支预测器的父类。BPredictor类中的predict()函数会调用BPred类的doPredict()函数,而doPredict()函数会调用BPred类的predict()函数(一个虚函数),实际会调用配置文件中对应子类的predict()函数。
连续的调用fetch()函数将会触发调用fakeFetch()函数,其从误预测分支的错误路径上获取指令。这些指令将被标记为假指令。
//src/libcore/FetchEngine.cpp
void FetchEngine::fakeFetch(IBucket *bucket, int32_t fetchMax)
{
I(missInstID);
#ifdef SESC_MISPATH
if(!issueWrongPath)
return;
ushort n2Fetched = FetchWidth;
do {
//......
dinst->setFake();
n2Fetched--;
bucket->push(dinst);
const Instruction *fakeInst = Instruction::getInst(missInstID);
if (fakeInst->isBranch()) {
if (!processBranch(dinst, n2Fetched))
break;
}else{
missInstID = fakeInst->calcNextInstID();
}
}while(n2Fetched);
nFetched.add(FetchWidth - n2Fetched);
nWPathInsts += FetchWidth - n2Fetched;
#endif // SESC_MISPATH
}
最后,当误预测分支执行时,它更新了FetchEngine对象并重新存储了正确的执行路径。
3.2 发射和调度(Issuing & Scheduling)
在发射阶段期间,指令从指令队列中获取(这些指令是在取指阶段放在指令队列中的),然后将其置于一个特定cluster的独立调度窗口中。调度包括何时一条指令的输入操作数就绪和何时指令被调度执行。直到被调度,每一条指令都按序(如 in program order)地处于处理器中。在调度和执行中,当指令就绪执行时它们是乱序执行的。之后,在退出阶段(retirement stage),指令按程序序(program order)被放回。
GProcessor对象中的issue()函数从指令队列中获取一定可配置数量的指令并试图将它们放进对应cluster的调度队列中。issue()函数为每条指令调用addInst()函数。如果addInst()函数因为一条指令调用失败,issue()函数返回,且issue()函数于下一个周期中再次尝试发射该条指令。
//src/libcore/GProcessor.cpp
int32_t GProcessor::issue(PipeQueue &pipeQ)
{
int32_t i=0; // Instructions executed counter
int32_t j=0; // Fake Instructions counter
//......
do{
IBucket *bucket = pipeQ.instQueue.top();
do{
I(!bucket->empty());
if( i >= IssueWidth ) {
return i+j;
}
I(!bucket->empty());
DInst *dinst = bucket->top();
//......
StallCause c = addInst(dinst);
if (c != NoStall) {
if (i < RealisticWidth)
nStall[c]->add(RealisticWidth - i);
return i+j;
}
i++;
bucket->pop();
}while(!bucket->empty());
pipeQ.pipeLine.doneItem(bucket);
pipeQ.instQueue.pop();
}while(!pipeQ.instQueue.empty());
return i+j;
}
在确认指令可以被发射前,addInst()函数会检查一些事情。检查事项如下:
- reorder buffer中是否还有空间;
- 是否存在空闲的目的寄存器;
- 对应cluster调度窗口中是否还有空间;
- 基于一条指令所使用的确切资源,它执行其他的一些检查。例如,对于loads,它将会确认loads最大数目还未达到;对于分支,它将会确认未完成分支(outstanding branches)的最大数目还未达到。该检查是通过调用该指令的确定Resource类对象的schedule()函数完成的。(Resources的例子是load/store单元或浮点乘法器)。
3.2.1 指令间的依赖
如果上述描述的GProcessor类中的addInst()函数执行成功,它会调用确定cluster(该cluster接下来会执行这条指令)的addInst函数。最后,一个该条指令的入口将会被添加到reorder buffer的尾端。
为了管理指令间的依赖(如:当一个指令的目的寄存器是另一条指令的源寄存器时),每个Cluster拥有一个DepWindow(dependency window)对象。该对象用于管理指令间的依赖。Cluster类中的addInst()函数接着调用与该Cluster相关联的DepWindow中的addInst()函数。
在DepWindow中,指令到目的寄存器的映射表被维护着。该映射表跟踪向每个寄存器进行写操作的的最近指令。当addInst()函数被调用时,向该表中查询被调度指令的源寄存器。指令间存在依赖关系,则可以查询到为该指令产生输入操作数的指令(即该源寄存器真的在映射表中)。当一条指令完成运行,如果映射该条指令的入口仍在表中,则清除该入口。
//src/libcore/Cluster.h
class Cluster {
private:
//......
protected:
DepWindow window;
const int32_t MaxWinSize;
int32_t windowSize;
GProcessor *const gproc;
//......
Resource *res[MaxInstType];
protected:
void delEntry() {
windowSize++;
I(windowSize<=MaxWinSize);
}
//......
public:
void newEntry() {
windowSize--;
I(windowSize>=0);
}
//......
}
//src/libcore/Cluster.cpp
void Cluster::addInst(DInst *dinst)
{
window.addInst(dinst);
}
//src/libcore/DepWindow.cpp
DepWindow::DepWindow(GProcessor *gp, const char *clusterName)
:gproc(gp)
,Id(gp->getId())
,InterClusterLat(SescConf->getInt("cpucore", "interClusterLat",gp->getId()))
,WakeUpDelay(SescConf->getInt(clusterName, "wakeupDelay"))
,SchedDelay(SescConf->getInt(clusterName, "schedDelay"))
,RegFileDelay(SescConf->getInt("cpucore", "regFileDelay"))
,nReplay("Proc(%d)_%s:nReplay", gp->getId(), clusterName)
{
char cadena[100];
sprintf(cadena,"Proc(%d)_%s", Id, clusterName);
resultBusEnergy = new GStatsEnergy("resultBusEnergy", cadena , Id, IssuePower
,EnergyMgr::get("resultBusEnergy",Id));
forwardBusEnergy = new GStatsEnergy("forwardBusEnergy", cadena , Id, IssuePower
,EnergyMgr::get("forwardBusEnergy",Id));
windowSelEnergy = new GStatsEnergy("windowSelEnergy",cadena, Id, IssuePower
,EnergyMgr::get("windowSelEnergy",Id));
windowRdWrEnergy = new GStatsEnergy("windowRdWrEnergy", cadena , Id, IssuePower
,EnergyMgr::get("windowRdWrEnergy",Id));
windowCheckEnergy = new GStatsEnergy("windowCheckEnergy", cadena, Id, IssuePower
,EnergyMgr::get("windowCheckEnergy",Id));
sprintf(cadena,"Proc(%d)_%s_wakeUp", Id, clusterName);
wakeUpPort = PortGeneric::create(cadena
,SescConf->getInt(clusterName, "wakeUpNumPorts")
,SescConf->getInt(clusterName, "wakeUpPortOccp"));
SescConf->isInt(clusterName, "wakeupDelay");
SescConf->isBetween(clusterName, "wakeupDelay", 0, 1024);
sprintf(cadena,"Proc(%d)_%s_sched", Id, clusterName);
schedPort = PortGeneric::create(cadena
,SescConf->getInt(clusterName, "SchedNumPorts")
,SescConf->getInt(clusterName, "SchedPortOccp"));
// Constraints
SescConf->isInt(clusterName , "schedDelay");
SescConf->isBetween(clusterName , "schedDelay", 0, 1024);
SescConf->isInt("cpucore" , "interClusterLat",Id);
SescConf->isBetween("cpucore" , "interClusterLat", 0, 1024,Id);
SescConf->isInt("cpucore" , "regFileDelay");
SescConf->isBetween("cpucore" , "regFileDelay", 0, 1024);
}
void DepWindow::addInst(DInst *dinst)
{
const Instruction *inst = dinst->getInst();
I(dinst->getResource() != 0); // Resource::schedule must set the resource field
if (!dinst->hasDeps()) {
dinst->setWakeUpTime(wakeUpPort->nextSlot() + WakeUpDelay);
preSelect(dinst);
}
}
上述构造函数中SescConf的定义是SConfig *SescConf=0;,此处便涉及了配置文件的使用。
class SConfig:public Config {
private:
protected:
// Redefine the following two methods so that the class works a
// little bit different.
//
// Instead of the original Config interface I have something a
// little bit more specific for the sesc configuration file. The
// first section of the configuration file has variables that
// point to sections. Example:
//
// bpred = 'myBPredSection'
// a = 1
// b = 1
// [myBPredSection]
// a = 2
// c = 2
//
// Results for getInt:
// getInt("bpred","a") = 1 // main section overides private section
// getInt("bpred","b") = 1 // only defined in main
// getInt("bpred","c") = 2 // only defined in section
//
// Remeber that the environment variable ALWAYS overides local variables:
// SESC_a = 7 // highest priority overide (a=7)
// SESC_bpred_a = 8 // whould use a = 7 instead. If SESC_a is not defined a = 8
// SESC_bpred_c = 7 // highest
// SESC_b = 7
// SESC_bpred_b = 7 // unless getInt("bpred","b") it is ignored
//
virtual const char *getEnvVar(const char *block,
const char *name);
virtual const Record *getRecord(const char *block,
const char *name,
int32_t vectorPos);
public:
SConfig(const char *name);
std::vector<char *> getSplitCharPtr(const char *block,
const char *name,
int32_t vectorPos=0);
};
extern SConfig *SescConf; // declared in SescConf.cpp
考虑下面的代码片段:
x: ld R1,0X1000;读取内存地址0x1000的内容值寄存器R1
y: add R1,R1,R2
上述代码中,指令y依赖于指令x。指令y是消费者,指令x是生产者。在本例中,于指令x上会调用addSrc()函数(在src/libcore/DInst.h中存在两个函数void addSrc1(DInst d)和void addSrc2(DInst d)),此时该函数的参数便是指令y。之后,在运行(execution)阶段,在指令x已经完成执行后,指令x可以唤醒指令y并调度指令y执行。另外,DInst y也会标记自己依赖于一条指令。
对于一条没有依赖的指令,指令会被调度执行。这通过生成一个于确定数量的时钟周期内执行Resource类的simTime()函数的回调事件完成。延时取决于固定的调度惩罚和依赖于该Resource的已就绪执行的指令数,因为每一个Resource于一个周期内仅仅可以执行一小固定数量的指令。
最后,映射表中的输出操作数将被设置为指向这条被调度的指令(即完成指令到目的寄存器的映射工作)。然后,消耗这个输出操作数的后续指令将依赖于该指令。
3.3 执行(Execution)
DepWindow对象或者调度一条指令进行执行,或者在必须首先执行的指令中设置指针。
对于每一种指令类型,都存在Resource的子类,如下图所示: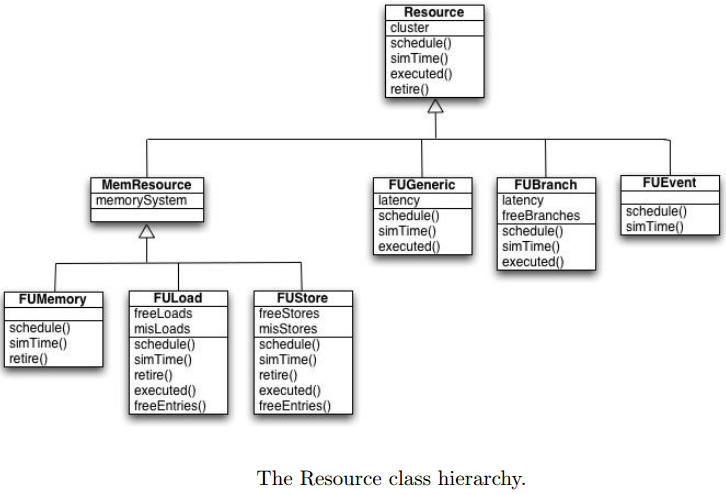
loads通过FULoad子类处理,stores通过FUStore处理, 其他杂的内存访问通过FUMemory处理,branches通过FUBranch处理,其他的所有指令通过FUGeneric处理。每一个子类都定义了一个simTime()函数,其模拟功能的执行。每一个子类也定义了一个executed()函数,其在执行完成后被调用。分支和整数操作的执行耗费一个时钟周期,浮点操作的运行需要若干个周期,而对内存的操作可能最多要耗费成百上千个周期。
Execution是通过Resource对象中的simTime()函数完成的。对于loads,FULoad将发送load到cache。对于stores,它将调度一个对于executed()函数的回调(stores被实际发送到cache是在退出(retirement)阶段,stores可能会沿着一个分支的错误路径进行)。对于所有其他的指令,一个回调会被调度去执行executed()函数。executed函数会调用与该Resource相对应的Cluster中的entryExecuted()函数。entryExecuted()函数会调用DepWindow对象中的simTimeAck()函数。(entryExecuted()和simTimeAck()两个函数都没有找到)。executed函数会调用与该Resource相对应的Cluster中的executed()函数。Cluster中的executed()函数会调用DepWindow对象中的函数首先标记该DInst为executed,故而,之后该指令将被退出。然后,它检查目的寄存器在表中的入口是否仍然存在,如果仍然存在,则清除该入口。之后需要消费该值的指令将不必等待。最后,它调用DepWindow中的executed()函数检查是否存在任意的指令依赖它。再次考虑上面的例子,DInst x 检查到DInst y不再依赖任意的其他指令。然后,通过生成一个对simTime()函数的回调事件使得y被调度执行。
//src/libcore/Resource.cpp
void FULoad::simTime(DInst *dinst)
{
Time_t when = gen->nextSlot()+lat;
// The check in the LD Queue is performed always, for hit & miss
iAluEnergy->inc();
stqCheckEnergy->inc(); // Check st-ld forwarding
cluster->getGProcessor()->getLSQ()->executed(dinst);
ldqRdWrEnergy->inc();
ldqCheckEnergy->inc();
if (dinst->isLoadForwarded()) {
dinst->doAtExecutedCB.scheduleAbs(when+LSDelay);
// forwardEnergy->inc(); // TODO: CACTI == a read in the STQ
nForwarded.inc();
}else{
if(dinst->isDeadInst()) {
// dead inst, just make it fly through the pipeline
dinst->doAtExecuted();
} else {
cacheDispatchedCB::scheduleAbs(when, this, dinst);
}
}
}
void FULoad::executed(DInst* dinst)
{
Resource::executed(dinst);
}
void Resource::executed(DInst *dinst)
{
cluster->executed(dinst);
}
//src/libcore/Cluster.cpp
void ExecutedCluster::executed(DInst *dinst)
{
dinst->markExecuted();
delEntry();
window.executed(dinst);//window是DepWindow对象
}
//src/libcore/DepWindow.cpp
// Called when dinst finished execution. Look for dependent to wakeUp
void DepWindow::executed(DInst *dinst)
{
const Instruction *inst = dinst->getInst();
#ifdef SESC_BAAD
dinst->setExeTime();
#endif
// MSG("execute [0x%x] @%lld",dinst, globalClock);
I(!dinst->hasDeps());
resultBusEnergy->inc();
windowCheckEnergy->inc();
windowSelEnergy->inc();
windowRdWrEnergy->inc(); // Add entry
windowRdWrEnergy->inc(); // check deps
windowRdWrEnergy->inc(); // Remove the entry
if (!dinst->hasPending())
return;
if (dinst->isStallOnLoad())
wakeUpDeps(dinst);
I(dinst->getResource());
const Cluster *srcCluster = dinst->getResource()->getCluster();
// Only until reaches last. The instructions that are from another processor
// should be added again to the dependence chain so that MemRequest::ack can
// awake them (other processor instructions)
const DInst *stopAtDst = 0;
bool replayDetected = false;
while (dinst->hasPending()) {
if (stopAtDst == dinst->getFirstPending())
break;
DInst *dstReady = dinst->getNextPending();
I(dstReady);
if (!dstReady->isIssued()) {
I(dinst->getInst()->isStore());
// Accross processor dependence
if (dstReady->hasDepsAtRetire())
dstReady->clearDepsAtRetire();
I(!dstReady->hasDeps());
continue;
}
if (dstReady->isExecuted()) {
// The instruction got executed even though it has dependences. This is
// because the instruction got silently killed (killSilently)
if (!dstReady->hasDeps())
dstReady->scrap();
continue;
}
if (dstReady->hasDepsAtRetire() && dinst->getInst()->isStore()) {
// Means that there was a memory dependence between this two memory
// access, and the they are performed in different processors
I(dstReady->isSrc2Ready());
I(dstReady->getInst()->isLoad());
#ifdef LOG_ENFORCEMENT
LOG("across cluster dependence enforcement (%p) pc=0x%x [addr=0x%x] vs (%p) pc=0x%x [addr=0x%x]"
,dinst
,(int)dinst->getInst()->getAddr() , (int)dinst->getVaddr()
,dstReady
,(int)dstReady->getInst()->getAddr(), (int)dstReady->getVaddr());
#endif
dinst->addFakeSrc(dstReady, true); // Requeue the instruction at the end
if (stopAtDst == 0)
stopAtDst = dstReady;
continue;
}
GI(dstReady->hasDepsAtRetire(),!dstReady->isSrc2Ready());
if (!dstReady->hasDeps()) {
// Check dstRes because dstReady may not be issued
I(dstReady->getResource());
const Cluster *dstCluster = dstReady->getResource()->getCluster();
I(dstCluster);
Time_t when = wakeUpPort->nextSlot();
if (dstCluster != srcCluster) {
forwardBusEnergy->inc();
when += InterClusterLat;
}
dstReady->setWakeUpTime(when);
preSelect(dstReady);
}else{
if (!replayDetected && dstReady->isJustWaitingOnMemory()) {
replayDetected = true;
// MSG("pc=0x%x dinst=%p @%lld",dinst->getInst()->getAddr(), dinst, globalClock);
nReplay.inc();
}
}
}
}
3.4 退出(Retirement)
在乱序处理器流水线的退出阶段,已经执行过的指令从reorder buffer的头部按原始的程序序(program order)被移除。典型地,每个周期最多3到4条指令可被移除。对于大部分指令来说,一旦它们执行完成并已到达reorder buffer的头部,它们总是会被移除。然而,stores直到退出阶段才被实际发送到cache。如果此时cache不能接受该store,该store将不能退出。
在SESC中,GProcessor对象于每个周期调用一次retire()函数。retire()函数取走reorder buffer头部的DInst(the DInst is the oldest instruction),并检查它是否可以被退出。首先,该函数通过检查executed标志(如上所述,该标志在执行阶段被设置)来确定该指令是否已经被执行。然后,它调用Resource对象的retire()函数去处理那条指令。
Resource对象的retire()函数返回一个成功代码指示该指令是否可以被退出。对于所有的指令除了stores外,指令总是可以被退出的。对于stores,retire()函数检查cache是否可以接受这个store,然后返回对应的代码。如果存在太多的未完成的stores(outstanding stores)或者如果存在内存保护的话,cache可能不能接受这个store。如果cache可以接受该store,一个内存请求将被发送到该cache用于store,接着,该指令便可以被退出。
Resource对象中的retire()函数也负责销毁该DInst对象。
在GProcessor对象中,retire()函数很适合用于检查何时处理器因为指令太多而导致停顿(如处理器不再退出指令)。如果一个处理器停顿太久,这很可能表明存在bug。
//src/libcore/GProcessor.cpp
void GProcessor::retire()
{
//......
robUsed.sample(ROB.size());
ushort i;
for(i=0;i<RetireWidth && !ROB.empty();i++) {
DInst *dinst = ROB.top();
if( !dinst->isExecuted() ) {
addStatsNoRetire(i, dinst, NotExecuted);
return;
}
// save it now because retire can destroy DInst
int32_t rp = dinst->getInst()->getDstPool();
bool fake = dinst->isFake();
I(dinst->getResource());
RetOutcome retOutcome = dinst->getResource()->retire(dinst);
if( retOutcome != Retired) {
addStatsNoRetire(i, dinst, retOutcome);
return;
}
//......
}
//src/libcore/Resource.cpp
enum RetOutcome {
Retired=0,
NotExecuted,
NotFinished, // for loads only
NoCacheSpace, // for stores and ifetch ops only
NoCachePorts, // for stores only
WaitForFence, // for ifetch ops only
MaxRetOutcome
};
RetOutcome Resource::retire(DInst *dinst)
{
cluster->retire(dinst);
dinst->destroy();
return Retired;
}
//src/libcore/Cluster.cpp
//retire()函数在Cluster类中是虚函数,ExecutedCluster是Cluster的子类。
void ExecutedCluster::retire(DInst *dinst)
{
//......
winNotUsed.sample(windowSize);
// Nothing
}