1.概述
异构多核处理器(HMP)可以在多样的工作负荷下提供高的执行效率,而程序调度是开拓这种效率的关键。论文提出了一种新奇的方法,即利用程序固有的特征在HMP上进行调度决策。所提出的方法将核(core)的配置和程序的资源需求映射到一个标准的多维空间,并使用(核的配置和程序的资源需求之间的)加权欧拉距离(Weighted Euclidean Distance—>WED)指导程序调度(在所映射的多维空间中,program-core匹配程度可以很容易地通过WED来度量)。
基本原则:成功的程序调度器必须能够以最小的性能和能量损失找到与程序相匹配的核。
2.相关工作
之前与HMP上程序调度相关的程序调度主要集中在优化子任务的调度。这些调度方法需要预先知道(或容易预测)工作负荷的性能/功耗比,这在根本上限制了它们的应用。论文中提出的方法不需要预先知道微体系结构所依赖的性能/功耗数据而进行调度。
Chen和John采用模糊逻辑计算program-core的匹配程度,并利用该结果指导程序的调度。但是,模糊逻辑的复杂性会随程序特征数的增加而成指数增长,故这种方法不具有好的扩展性。论文中的调度方法是可扩展的,即使程序的特征数为四或者更多。
3.框架
多维program-core匹配的思想来源:programs和cores可以通过一系列正交的特征来描述。通过映射这些来自程序和核的特征到一个标准的空间中,我们可以形象化地表示程序和核之间的相关性,并简化program-core匹配。
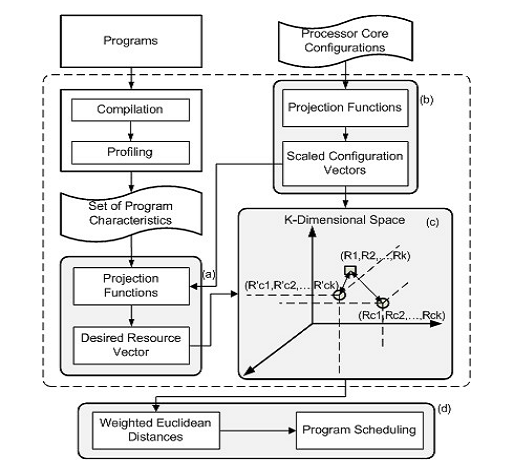
4.框架描述
以下描述中,向量
程序首先被编译并剖析,以获得程序固有特征的K个集合X1,X2,…,XK,其中Xi=(xi0,xi1,xi2,…,xin)是描述程序特征i(i=1,2,..,K)的向量。定义gi是一个映射函数,它可以将特征Xi转换为程序期望的资源需求Rpi,如:
Rpi=gi(Xi)=gi(xi0,xi1,xi2,…,xin)。我们拥有程序的期望资源向量:RD=(Rp1,Rp2,Rp3,…,Rpk)=(g1(X1),g2(X2),…,gK(XK))。该向量指向程序于K维空间中的期望配置节点,如图1中的(c)。另一方面,每个处理器核拥有一个配置向量(C1,C2,..,Ck),其中Ci对应程序特征Xi(i=1,2..,K)。同样地,这些向量也可以通过一套映射函数被转换为一个于K维空间中可测量的配置向量RC=(Rc1,Rc2,Rc3,…,Rck)。一旦所期望的资源向量RD和配置向量RC被映射到相同的空间,它们两个之间的距离就变得自然可度量并可反映程序和核之间的匹配程度。明确地说,较大的距离导致程序和核之间较少的兼容性,进而产生较低的执行效率。注意到,并不是向量的每一维对匹配程度的贡献都是相等的。因此,我们使用K维空间中的WED作为program-core匹配程度的度量标准,公式如下:
其中,
5.映射函数
映射函数被用来将程序特征和核配置映射到一个标准的K维空间。
5.1核配置映射函数
硬件资源遭受着收益递减效应1,即额外增加硬件资源量在边际收益上并不是成比例增长的(diminishing return effect:the additionanl hardware resource yields less than proportional increase in the margin benefit)。收益递减效应暗含在核配置映射函数中:随着配置值的增加,邻近配置间的空间将减小(the spacing between adjacent configurations decreases as the value of the configuration increase)。故,映射函数如下:
其中,
5.2程序特征映射函数
与硬件配置相一致,论文中检查了三个重要的程序特征:ILP(instruction level paralleism指令级并行)、barnch predictability and data locality。这些特征的映射函数被用来标识期望的issue width,branch predictor size and data cache size。
- Desired Issue Width
使用指令依赖距离去描述程序的ILP。典型地,对于一个给定的依赖距离分布,依赖距离长的指令越多,程序所拥有的ILP就越多,因此其所期望的issue width越大。根据依赖距离 将指令分为四组:
令Xdep,i表示程序中依赖距离落在组i(i=1..4)中的指令所占的比例,因此程序依赖距离向量为(Xdep,1,Xdep,2,Xdep,3,Xdep,4)。因此,分布质心(即加权平均)表示程序需求的平均issue width:组标号 依赖距离 group 1 1 group 2 2-3 group 3 4-7 group 4 ≥8 其中,Wi,i=1..4,是空间中issue width维的映射坐标,表示从1到8的issue width。Rissue=∑4i=1Xdep,i∗Wi∑4i=1Xdep,i
- Desired Branch Predictor Size
使用分支转变率表示程序的分支预测能力。通常来说,具有极低或极高转变率的分支指令很容易预测,并且当转变率接近50%时,分支变得愈难预测。因此将转变率分成10个buckets:[0,0.1],[0.1,0.2],… ,[0.9,1.0]。Xbr,i表示转变率落在bucket i(i=1..10)中的分支指令数,因此,可以得到分支转变率向量(Xbr,1,Xbr,2,…,Xbr,10)。因为落在bucket[0.4,0.5]和bucket[0.5,0.6]中的分支指令最难预测,所有将它们与容量最大的分支预测器相关联。落在bucket[0.3,0.4]和bucket[0.6,0.7]中的分支指令相对容易预测,所以将它们与一个较小的分支预测器相关联。类似的,该规律可应用到buckets[0.2,0.3]和[0.7,0.8]及buckets[0.1,0.2]和[0.8,0.9]中。因此,计算一个程序所需的平均分支预测器大小的公式如下:其中,Bi,i=1..4是空间中分支预测维的坐标(Rbranch=(B1∗(Xbr,2+Xbr,9)+B2∗(Xbr,3+Xbr,8)+B3∗(Xbr,4+Xbr,7)+B4∗w∗(Xbr,5+Xbr,6))∑4i=2Xbr,i+∑9i=7Xbr,i+w∗∑6i=5Xbr,i B1<B2<B3<B4 )。Buckets[0.0.1]和[0.9,0.1]在此不被考虑,因为在这些范围内分支指令很容易预测(其产生的分支预测器容量很小,可忽略)。w被用来调节最大分支预测器的权重,设置为α×Pcond 。α 是由实验测得的,与指令issue width成比例。它用以保证一个事实:随着issue width变宽,分支错误预测损失也增加,因此需要一个更大的分支预测器以保证较高的预测精度。Pcond是指令混合中条件分支的比例,较大的Pcond将导致大量的难于预测分支,因此大分支预测器的权重应该高些。
- Desired L1 Data Cache
期望L1数据缓冲是一个处理器核为高效利用程序数据局部性所需的数据缓冲大小。论文中使用Mattson’s stack distance distribution度量程序的数据局部性。令Hi(i=1..4)为可能的L1数据缓冲大小,且H1<H2<H3<H4 ,并且令Xstk,i(i=1..4)分别为访问数据时堆栈距离落在范围为[0,H1],(H1,H2],(H2,H3],(H3,H4]中的访问次数。所以,计算一个程序的期望L1数据缓冲大小的公式如下:其中,Rcache=∑4i=1Xstk,i∗H′i∑4i=1Xstk,i H′i 表示数据缓冲大小Hi(i=1…4) 的缩放坐标。
对program-core匹配的影响程度从高到低排序如下: issue width>cache size>branch predictor size。故论文中,issue width维、cache size维和branch prediction维的权重分别设为0.8,0.2和0.1。
6.启发式调度算法
WED表示了程序资源需求和核硬件资源提供之间的匹配,其值越小,匹配度越好,程序执行效率也就越高。最优调度器应该使得被调度的program-core对的总距离最小,但是这样就是一个NPC问题(简单实现时,复杂度为
Let Pj be the j-th program in the program queue (j=1..M).
Let Ci be the processor core i. (i=1..N)
for j ( 1 .. M)
for i ( 1.. N)
if (Ci is available && min_dist > distance(Pj,Ci))
min_dist = distance(Pj,Ci);
k=i;
end if
end for
schedule Pj to Ck;
mark Ck as unavailable;
end for
上述启发式算法是基于先来先服务(FCFS)的,对于每一个程序,它将分配一个与之距离最小的核供其运行,时间复杂度为
另外,论文中使用如下三种算法与该启发式算法进行对比:
| 调度算法 | 原理 |
|---|---|
| Hardware Oblivious Scheduling(baseline) | 不考虑底层硬件,FCFS |
| Min EDP Scheduling | 调度使得全局EDP最小,它假设每个program-core对的EDP都已预知,提供best case方案 |
| Max EDP Scheduling | 调度使得全局EDP最大,它假设每个program-core对的EDP都已预知,提供worst case方案 |
7.实验方案
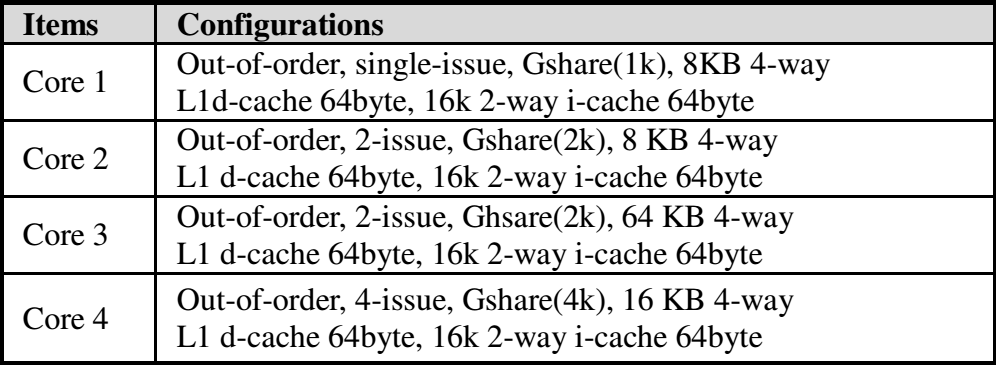
为了验证WED模型,论文中,使用了多种乱序超标量体系结构处理器(拥有不同的instruction issue width、L1 cache size 和branch predictor size,如表1)。为了验证所提出的启发式算法,构造出假定的single-ISA四核异构处理器如表2所示。

实验的工作负载由源自Mibench,MediaBench和SPEC CPU2000的基准程序组成。每个程序被编译成具有最大配置的Alpha-ISA。论文中,作者使用源自Simplescalar工具中被广泛使用的改良SimProfile去勾画程序,并收集上述的程序特征;采用Wattch2去获得每个基准程序的性能和功耗数据。为了评价所提框架的效力,作者从三个方面对所提调度模式进行了评估:EDP3、energy和makespan4。
8.结果和分析
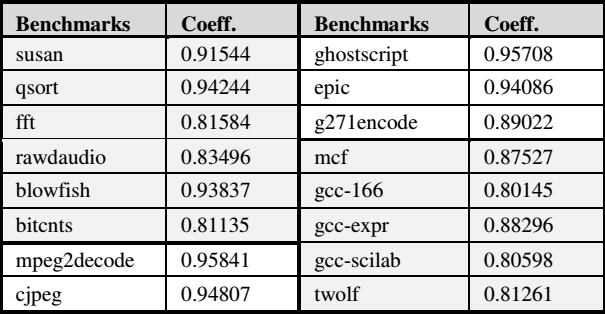
由表3,可知:
- WED与EDP显著相关,即说明WED可以合适地代表程序在一个确定核上的执行效率;
- 输入集几乎不会对程序的固有特征产生影响。
为了评估所提出的程序调度模式,作者从表3所示到基准程序中选择拥有不同特征的程序组成150个不同的程序组合,每个组合包含四个程序。图2显示了对这些不同工作负荷进行调度的结果箱线图。
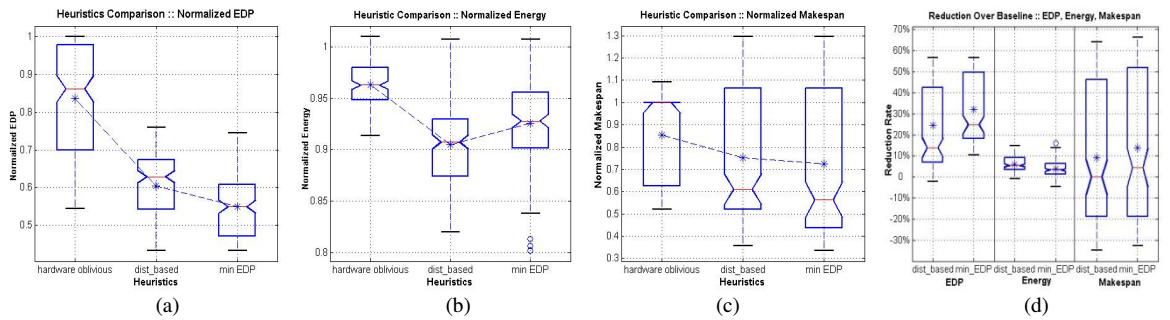
由箱线图可知:
- 所提出的基于距离的调度相对于基线调度具有显著的改善(在EDP上平均减少了24.5%,在能量上平均减少了6.1%,在makespan上平均减少了9.1%)。
- 与最小EDP调度相比,基于距离的调度在节能效果上表现更佳(6.1%VS3.9%),但在makespan上降低较少(9.1%VS13.8%)。然而,由于两者的箱线图存在着较多的重叠部分,故它们在makespan减少上的不同于统计上并不显著。
总之,在HMP系统中,基于距离的调度可以在吞吐量和能量间取得一个好的平衡。
参考文献
- Chen, Jian, and L. K. John. “Efficient program scheduling for heterogeneous multi-core processors.” Proceedings of the 46th Annual Design Automation Conference ACM, 2009:927—930.
指在其他技术水平不变的条件下,在连续等量地把一种可变要素增加到其他一种或几种数量不变的生产要素上去的过程中,当这种可变生产要素的投入量小于某一特定值时,增加该要素投入所带来的边际产量是递增的;当这种可变生产要素的投入量增加并超过这个特定值时,增加该要素投入所带来的边际产量是递减的。↩
Wattch: A Framework for Architectural-Level Power Analysis and Optimizations.↩
EDP考虑了能量和效率两者,被广泛地用以度量程序的执行效率。↩
Makespan是一组程序开始到完成之间的时间,被用来度量吞吐量。↩